基于 marked.js 定制一个 Markdown 解析器
2022-03-28 17:00:00
marked.js 是一款轻量级的快速 Markdown 解析器,可以运行在浏览器或服务器( Node.js 环境)上,著名的 Hexo 和 docsify 等工具都依赖它,截至 2022 年 1 月 20 日,在 Github 的 Star 数是 26700+
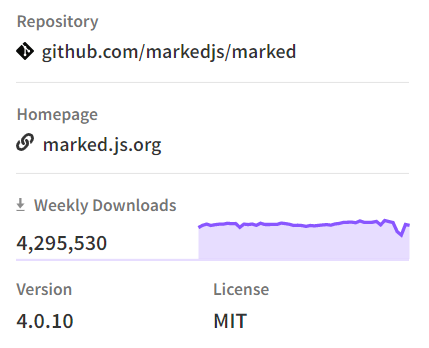
在 npm 的周下载量高达 429 万,其火热程度可见一斑:
为什么要改造 marked.js
marked.js 用来解析一般的 Markdown 是完全够用的,但是我遇到了几个问题:
- 把
$包裹的 LaTeX 公式解析成了普通文本 - 把 LaTeX 公式的换行符
\\转义成了\,导致不能正常换行 - 把 LaTeX 公式的下标
_解析成了斜体<em>标签 - 无法把
?>开头的内容解析成提示(docsify 是可以做到的)
注:我所使用的 marked.js 版本号为 4.0.10,后续版本是否有问题不得而知。
已知的解决方案
问题 1, 2, 3 可以统一成对 LaTeX 公式的支持问题。不妨以 Hexo 框架对 Markdown 的解析流程来分析问题的产生原因:
Hexo 先读取 Markdown 文件,把字符串交给 marked.js 解析,$包裹的内容在 marked.js 看来无特殊含义,当作普通文本处理,然后转义机制把\\转义成了\,下标_被解析成了斜体<em>标签,最后 MathJax 渲染的时候,原 LaTeX 代码已经被动过手脚,于是出现异常。
方案一:\\被转义成\,那么\\\\就被转义成\\,那么 4 个反斜线即可正常换行。下标_可以用\_替代。属于最次的解决方案,修改成本大,通用性差,修改后的 Markdown 文件迁移到其他平台又会出问题。
方案二:修改 marked.js 源代码,使其不再对\\进行转义,也不再把_解析成<em>标签,详细步骤可以参考使Marked.js与MathJax共存。属于治标不治本,因为不能保证还有无其它潜在的字符冲突,没有彻底解决问题。
方案三:从源头上解决问题,替换 Hexo 的解析引擎,比如采用 hexo-renderer-pandoc 来解析。事实上,我以前确实是用的这种解决方案,但是它也有局限。第一,依赖 Pandoc,可我只想纯采用 js 语言。第二,无法根据个人需求深度定制。第三,我不想放弃 marked.js。
注:以上三种方案参考了天空的城的博客 Hexo下mathjax的转义问题。
我的解决方案
我觉得这个问题实在是太好解决了,好解决的前提是你得抓住问题 1, 2, 3 的本质,就一句话:
$包裹的内容在 marked.js 看来无特殊含义。
那么我只要让 marked.js 认为$包裹的内容有意义,并且对它不做任何处理,原封不动的返回不就行了嘛。换句话说,叫做:
扩展 marked.js 的语法。
按照这样的思路,连带着把问题 4 也解决了,我让它认为?>是有意义的即可。不止如此,以后遇到新的需求,我仍然可以随心所欲地扩展语法,这样才不失为解决问题的上策。

那么,我需要扩展两个功能:
- 扩展
$语法 - 扩展
?>语法
问题又来了,实现这样的功能是否需要改动 marked.js 的源代码?若需改动,如何改。若不需改动,又当如何?
源码机制分析
好在我找到一篇有帮助的教程,作者明确说明,得改,必须改动源代码。

于是我也去逐字逐句地阅读了 marked.js 的源代码,彻底弄清楚了它解析 Markdown 的原理。整个源代码的结构如下:
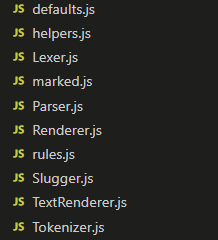
marked.js提供了入口函数,把 Markdown 字符串输入进去,它会返回解析后的 HTML。所以,从它开始读起。首先,词法分析器Lexer类对字符串进行分析,得到tokens。然后,把tokens交给解析器Parser类,得到 HTML。

Lexer.js得到 blockTokens 和 inlineTokens 两种 token,分别代表 HTML 的块级元素和行级元素:
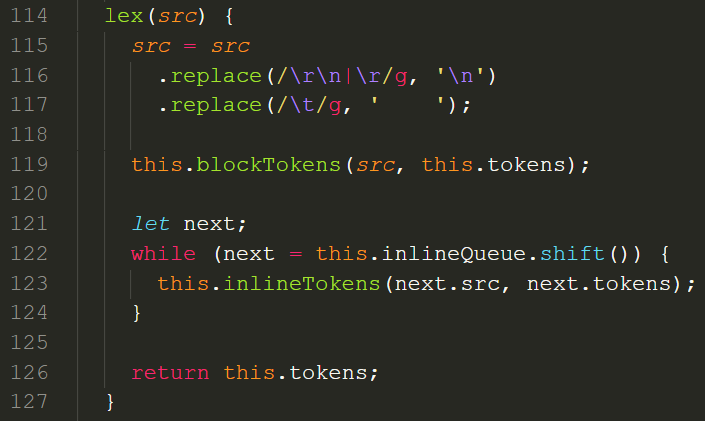
以 blockTokens 为例,在一个 while 循环中,对字符串src进行匹配,newline,code,fences,header,......,挨个尝试,直到匹配到一个 token:
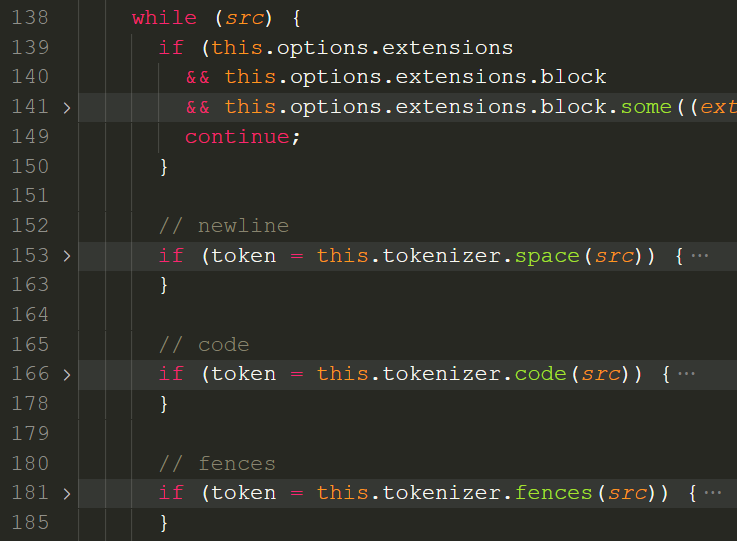
比如,匹配到 list 列表后,先把对应的字符串从src中掐掉,再把得到的 token 压进tokens数组中。

那么 token 究竟是怎么匹配出来的,需要阅读Tokenizer.js。每种块级元素和行内元素在 Tokenizer 类中都有对应的成员函数,在成员函数里定义了生成 token 的具体方法。
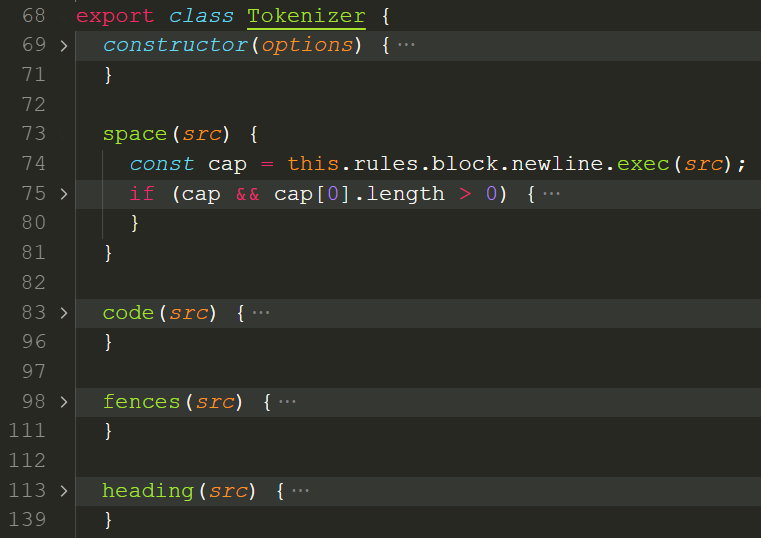
下面需要重点关注 rules,阅读rules.js。
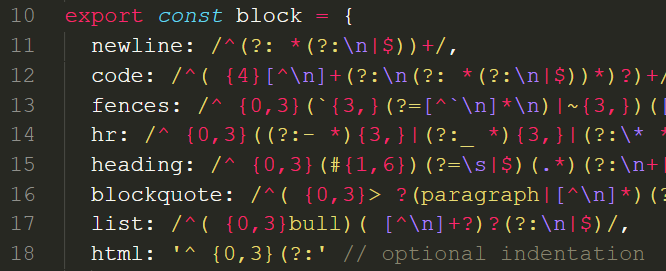
原来rules.block.newline是一个正则表达式,通过执行exec()方法就可以对字符串进行匹配。
到此为止,弄清楚了词法分析器Lexer类和分词器Tokenizer类是如何从字符串中提取出 token 的,下面解析器Parser类将对 token 进行解析。阅读Parser.js,它通过 for 循环对tokens进行遍历,根据每个 token 的 type 属性选择对应的渲染方式。
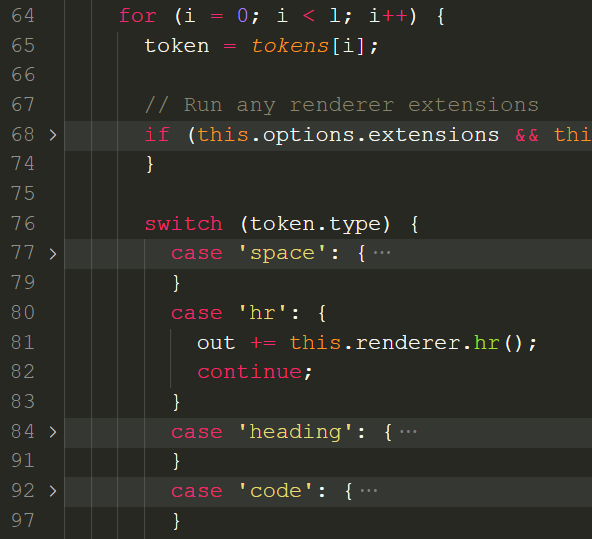
进入渲染环节,需要阅读Renderer.js,每种块级元素和行内元素在 Renderer 类中都有对应的成员函数,定义了具体渲染成什么样:
官方文档也给 Renderer 部分提供了明确的 API,并指出用户可以通过marked.use()定制成自己想要的渲染方式。

不过,官方给出的定制自由度是不够的。自由度是不够是什么意思呢,官方按照内置的语法,把 Markdown 帮你解析好,你只能参与渲染这一最末端的环节,你可以把 blockquote 的渲染方式从:
blockquote(quote) {
return '<blockquote>\n' + quote + '</blockquote>\n';
}
定制成:
blockquote(quote) {
return '<div>\n' + quote + '</div>\n';
}
但你没法决定什么样的语法被理解成 blockquote。总之,在不改动 marked.js 源代码的前提下,可以定制渲染,却不能定制语法,所以我们要改动源代码。
扩展$语法
通过之前的分析,已经搞清楚了 marked.js 的工作机制,那么再进行语法扩展简直就是信手拈来了。

第一步,编写正则表达式,用于匹配$符号:
/* rules.js */
// 在源码基础上增加了latex
const inline = {
latex: /^\${1,2}[\s\S]*?\${1,2}/,
...
}
第二步,把$符号从 text 的正则表达式中剔除:
/* rules.js */
// 在源码基础上对text进行修改
const inline = {
text: /^(`+|[^`])(?:(?= {2,}\n)|[\s\S]*?(?:(?=[\\<!\[`*_\$]|\b_|$)|[^ ](?= {2,}\n)))/,
}
// 如果开启了gfm,gfm的text也需要修改
inline.gfm = merge({}, inline.normal, {
text: /^([`~]+|[^`~])(?:(?= {2,}\n)|(?=[a-zA-Z0-9.!#$%&'*+\/=?_`{\|}~-]+@)|[\s\S]*?(?:(?=[\\<!\[`*~_\$]|\b_|https?:\/\/|ftp:\/\/|www\.|$)|[^ ](?= {2,}\n)|[^a-zA-Z0-9.!#$%&'*+\/=?_`{\|}~-](?=[a-zA-Z0-9.!#$%&'*+\/=?_`{\|}~-]+@)))/
});
第三步,给 Tokenizer 类增加成员函数:
/* Tokenizer.js */
// 在源码基础上增加latex成员函数
latex(src) {
const cap = this.rules.inline.latex.exec(src);
if (cap) {
return {
type: 'latex',
raw: cap[0],
text: cap[0].replaceAll('$', ''), // 用于去除首尾的$符号
};
}
}
第四步,给 Lexer 类增加 token 判定:
/* Lexer.js */
inlineTokens(src, tokens = []) {
...
while (src) {
// 在源码基础上增加latex的inlineToken
if (token = this.tokenizer.latex(src)) {
src = src.substring(token.raw.length);
tokens.push(token);
continue;
}
}
}
第五步,增加 Parser 类的 token 解析:
/* Parser.js */
parseInline(tokens, renderer) {
...
for (i = 0; i < l; i++) {
...
switch (token.type) {
// 解析latex的inlineToken
case 'latex': {
out += renderer.latex(token.text);
break;
}
...
}
}
}
第六步,给 Renderer 类增加成员函数:
/* Renderer.js */
// 在源码基础上增加latex成员函数
latex(tex) {
return tex; // 这里渲染成什么,可以视需求而定
}
到此为止,改造后的 marked.js 便拥有了解析 LaTeX 的能力。之后,可以选择原封不动地输出,由 MathJax 客户端渲染,也可以采用 MathJax 服务端渲染 LaTeX。
扩展?>语法
Markdown 使用>表示引用,?>和>上是一样的,我们可以直接在 blockquote 的基础上进行语法扩展。
第一步,修改 blockquote 的正则表达式,使其能匹配?>符号:
/* rules.js */
const block = {
// 在源码基础上修改blockquote
blockquote: /^( {0,3}(>|\?>) ?(paragraph|[^\n]*)(?:\n|$))+/,
}
第二步,修改 blockquote 的 token:
/* Tokenizer.js */
blockquote(src) {
...
if (cap) {
const regexp = /^ *(>|\?>) ?/gm;
const text = cap[0].replace(regexp, '');
return {
...
// 在源码基础上增加了flag,用于标注是>还是?>
flag: cap[0].match(regexp)[0].trim()
};
}
}
第三步,修改 blockquote 的 token 解析方式,把token.flag传给渲染器:
/* Parser.js */
case 'blockquote': {
...
out += this.renderer.blockquote(body, token.flag);
...
}
第四步,修改 blockquote 的渲染方式:
/* Renderer.js */
blockquote(quote, flag) {
if (flag == '>') {
return '<blockquote>\n' + quote + '</blockquote>\n';
}
return '<div class="warn">\n' + quote + '</div>\n'; // 具体如何解析,视需求而定
}
结尾
总结一下本文:由于网上已知的 3 种解决方案都不能满足我的需求,于是我通过分析源代码,扩展了 marked.js 的语法,彻底解决了 marked.js 的一些痛点,以后再有新的需求也可轻松实现。

基于 marked.js 定制一个 Markdown 解析器
https://qingyayaya.github.io/post/基于 marked.js 定制一个 Markdown 解析器/